





Protocol Update: Announcing the Theoriq Agent Reputation Layer

Theoriq builds accountability infrastructure for autonomous agents. The vaults, the swarms, $THQ staking all serve the same thesis: agents operating onchain need economic enforcement, not just access controls. Reputation is the data layer that makes that enforcement meaningful.
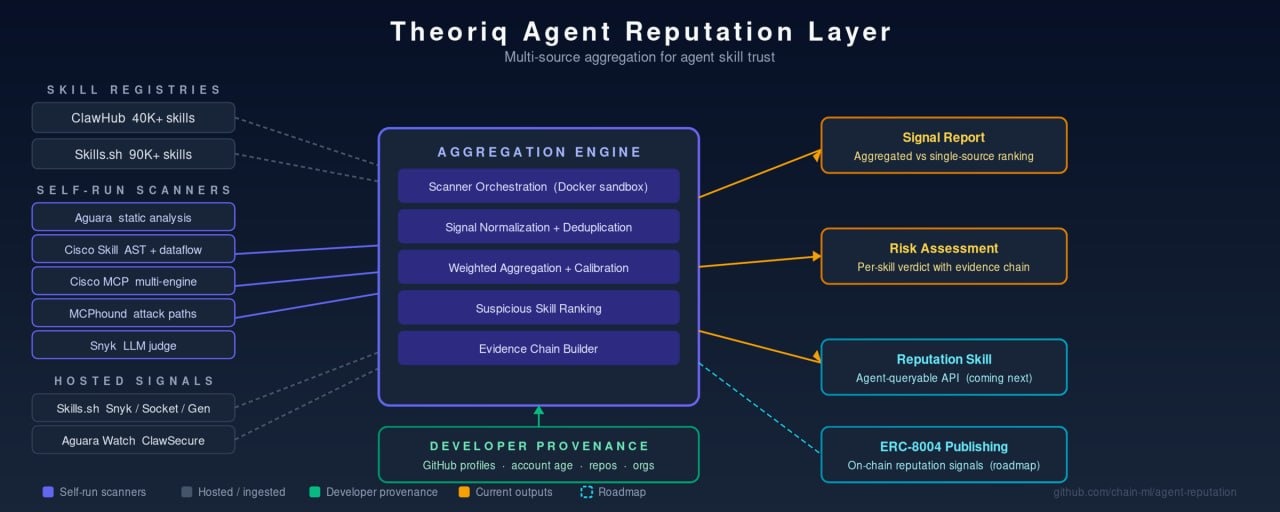
Today we are releasing the Theoriq Agent Reputation Layer as open-source software under an MIT license. It aggregates signals from existing security scanners into a unified reputation layer for the agent skill ecosystem. Not another scanner. A meta-layer that normalizes and combines evaluator signals, applied to the ecosystem as it actually exists today. Aggregated signals will be published onchain through ERC-8004, the reputation and validation standard built by contributors from MetaMask, the Ethereum Foundation, Google, and Coinbase.
When we wrote the Theoriq litepaper, agent reputation was a protocol design question. How should evaluators produce quality signals? How should staking align incentives? How should agents decide whether to trust each other?
Those questions mattered then. They matter more now. But the context has changed dramatically.
The ecosystem arrived
In late 2024, MCP was a proposal. Today it has nearly 100 million monthly SDK downloads. OpenAI, Anthropic, and Block co-founded the Agentic AI Foundation to govern it as a universal standard. The skill format is converging, and the ecosystem is exploding.
ClawHub lists 40,000+ skills while Skills.sh indexes 90,000+. Security has not kept pace. The ClawHavoc attack in February planted over a thousand malicious skills on ClawHub, and that was a straightforward supply chain attack. The more subtle risks are harder to catch and already emerging: skills that behave differently after installation, tools that exfiltrate context through side channels, skills vulnerable to prompt injections, agents that slowly drift from their stated purpose.
There are 10+ scanning engines and signal sources built by different teams using fundamentally different detection approaches: LLM judges, AST and dataflow analysis, NLP-based rule evaluation, multi-engine MCP scanning, attack path detection, supply chain checks. Skills.sh aggregates three of them for its own registry. ClawHub recently added VirusTotal. But as far as we have seen, there is no broadly adopted cross-registry aggregation layer. No widely used system combines scanner signals with developer credibility data. And there is no structured reputation feed that agents themselves can query before trusting a skill.
From protocol concepts to working code
The Theoriq litepaper described evaluators as specialized agents that produce quality signals contributing to reputation. Security scanners fit that pattern well: independent evaluators, each with different detection strengths and blind spots, producing quality signals about skills.
We have been operationalizing these ideas. Not by asking the world to adopt a new protocol, but by building practical open-source tooling that addresses today's problems and draws on the thinking we have done about reputation, evaluation, and trust.
The Agent Reputation Layer aggregates signals from existing scanners, including Snyk, Aguara, Cisco AI Defense, Socket, Gen Agent Trust Hub, MCPhound, and ClawSecure, into a unified reputation layer. It normalizes and combines evaluator signals across registries, producing a combined assessment that is more useful than any individual source.
Why Theoriq builds this
This connects directly to what we already operate.
Theoriq runs AlphaSwarm and GoldSwarm, autonomous AI agent swarms that curate yield strategies across DeFi for AlphaVault and Theoriq Gold Vault. Today these swarms operate within Theoriq's own infrastructure. As the agent ecosystem matures and swarms begin incorporating third-party tools and skills, reputation becomes the prerequisite for which tools an autonomous system should trust. We are building this infrastructure now because we operate agent swarms and understand firsthand what they will need. As MCP skill adoption expands into DeFi, every agent executing financial strategies onchain will need to verify the tools it depends on before trusting them. That is the trajectory that makes reputation infrastructure essential, not optional.
The Theoriq protocol's evaluator network, described in the litepaper, coordinates signal quality through staking. Scanner operators and signal providers align incentives around accuracy through $THQ, putting skin in the game so that reputation signals stay honest as the system scales. Reputation is a new layer in the same accountability architecture that governs how our vaults operate: identity, commerce, authorization, and economic enforcement.
This is that architecture applied to a new domain: verifying the tools that agents depend on. ERC-8004, with its Reputation Registry and pluggable Validation Registry already live on Ethereum mainnet and multiple L2s, is the publication layer that makes these signals discoverable by any agent in the ecosystem.
Three signal families
The system combines three types of signals that are individually useful but qualitatively different together.
Scanner findings tell you what the code does. Skills do not exist in isolation. They are backed by MCP servers and clients, and the system analyzes those too where the source is accessible. Each scanner uses different techniques and they disagree in informative ways. One scanner flags a skill as CRITICAL while five others call it CLEAN. That disagreement is data: either one scanner is catching something others miss, or it is the leading source of false positives. Both answers improve the system.
Developer provenance tells you who built it. GitHub account age, contribution history, published repositories, organization membership. A brand-new account with zero repos publishing dozens of skills is a different risk profile than an established developer with years of public work.
Ecosystem metadata tells you how the skill sits in the broader landscape. Download counts, cross-registry presence, version history, community signals.
No single signal family is sufficient. The interesting findings come from combining them.
What we have found
We have been running this system against live data from Skills.sh and ClawHub. Some early findings from the proof of concept:
Provenance signals surface things scanners miss entirely. We recently observed a publisher account that was less than a week old, had zero repositories and zero organization members, and had published a large number of skills. These dominated the suspicious ranking. No individual scanner would flag this pattern because scanners analyze code, not publishers. But for anyone deciding whether to install a skill, publisher credibility is a first-order concern.
Aggregation reranks massively. Skills that sit at rank 57 or rank 295 in a scanner-only ordering jump into the top 25 when you add developer credibility signals. The combined ranking operates in a genuinely different dimension than any single scanner.
Scanner disagreement is where the value lives. When one scanner says CRITICAL and five others say CLEAN, you either have a false positive to calibrate or a true finding to investigate. Across our initial dataset, a small but consistent fraction of skills show exactly this pattern. Resolving those disagreements, through human review and cross-referencing with provenance, is where multi-source aggregation proves its worth over any individual tool.
The hard problem is avoiding amplification. If you naively take 10 scanners each with a 5% false positive rate and flag anything any scanner flags, you get roughly a 40% flag rate (assuming independence). The system becomes noisier than any individual scanner, which is the opposite of useful. We are building the calibration layer: per-scanner precision profiling, correlation analysis, weighted aggregation strategies. The goal is a system where the combined output is more precise than the best individual scanner, not less.
Why open source
Trust infrastructure has to be transparent. A black-box reputation system asks you to trust the system that is telling you what to trust. That is circular and we do not think it works.
There is also a structural reason. The system gets better with more scanner adapters, more data sources, more registries covered. Scanner diversity matters more than any proprietary advantage. Every new scanner integration makes the aggregated signal more valuable for everyone.
And there is something genuinely new about this ecosystem. The users of a reputation system for agent skills are increasingly agents themselves, and agents can write code. An agent can scan a skill, contribute the results back, and query the system before installing something, all programmatically. The contributors, the users, and the product are converging.
What is in the release
The repository includes:
- Multi-scanner orchestration with five scanner adapters running in sandboxed Docker containers.
- Public data ingestion from ClawHub, Skills.sh audits, Aguara Watch, and ClawSecure.
- Developer credibility enrichment via GitHub's GraphQL API.
- Suspicious skill ranking across registries with a combined signal report comparing aggregated versus single-source detection.
- A live test playbook for end-to-end validation against real data.
The architecture is scanner-agnostic. New scanners plug in as adapters with a standard interface. The system is designed to get better as the ecosystem adds more detection engines.
What is next
The most important near-term milestone is a reputation-checking skill: a tool that any agent can invoke before installing another skill. You ask your agent to add a new MCP server, and before it does, it checks the reputation system. That requires a hosted backend to run and cache scan results so queries are fast and do not require every user to run scanners locally. That is what we are building toward next.
We are also looking to partner with skill marketplaces to make reputation data available where developers and agents are already discovering skills. Embedded badges and risk signals at the point of installation are where this has the most impact.
The scope of what needs analyzing is expanding too. Today most skills are backed by MCP servers with inspectable source code. Increasingly, skills will be thin wrappers that call external APIs, and the interesting behavior lives on the server side, not in the skill definition. Reputation needs to follow that chain: analyzing not just the skill but the API servers and clients it depends on.
Longer term
Beyond skill-level scanning, the aggregation engine is a foundation for broader agent reputation: tracking the quality and trustworthiness of agents as a whole, not just the skills they use. That is the next step on the path to reliable, governed agents. Eventually it connects to the harder questions: can you trust an agent enough to let it manage a transaction, curate a portfolio, or operate autonomously on your behalf?
The identity and accountability frameworks are converging. AAIF, NIST, OWASP's Top 10 for Agentic Applications, OpenID's agentic identity work. We see the reputation layer as a complement: the frameworks define what good governance looks like, and reputation systems provide the data to check whether agents are meeting those standards.
The onchain infrastructure is already in place. ERC-8004 launched in January 2026 across Ethereum mainnet and multiple L2s. Our goal is to produce high-quality aggregated signals and publish them through that standard, making assessments discoverable by any agent in the Ethereum ecosystem. The Theoriq protocol's evaluator network can serve as the coordination layer, with $THQ staking to align incentives around accuracy.
We are drawing on these ideas and contributing them to the open innovation ecosystem rather than waiting for the ecosystem to come to us. The agent world is moving fast and we want to move with it.
Get involved
This is early-stage work and we are looking for collaborators.
If you build or maintain a scanner, we have adapter interfaces ready. Plugging in a new detection engine directly improves the system for every user.
If you operate a registry or marketplace, we would like to talk about integration: reputation badges, API access, shared ground truth datasets.
If you are a security researcher, we have concrete disagreements in the data that need human review. Come look at them with us.
If you are part of the Theoriq community, the agent evaluator network has always been part of the Theoriq protocol roadmap and $THQ token design. We are launching it as a public good, open sourcing without token incentives to gather developer and researcher feedback on its own merits. As the evaluator network matures, $THQ staking will align scanner operators and evaluator nodes around accuracy, the same accountability mechanism described in the Theoriq litepaper. Onchain integration via ERC-8004 is on the roadmap.
The open source repo is published here: github.com/chain-ml/agent-reputation
About Theoriq
Theoriq is a DeFi strategy curator. It curates on-chain vaults that turn tokenized assets into risk-managed yield: curators set the strategy and the risk limits, and AI-assisted systems execute and monitor within them. Its flagship vault, AlphaVault ETH, applies this framework to ETH-native yield, and the Theoriq Gold Vault extends it to tokenized gold.

